Gpt 4.1 Models Are Here… Smarter, Faster, And More Affordable Ai
OpenAI has just launched its newest family of AI models called GPT-4.1. Released on April 14, 2025, these new models bring major improvements in coding abilities, following instructions, and processing large amounts of information at once.
What’s new in GPT 4.1?
OpenAI has introduced three new models: GPT-4.1, GPT-4.1 mini, and GPT-4.1 nano. Each targets different needs, with the full GPT-4.1 being the most powerful, mini offering a balance of performance and cost, and nano being the smallest and most affordable option.
These models can now handle up to 1 million tokens of information at once, that’s roughly 750,000 words, more than the entire text of “War and Peace” to be clear… for input not an output.
Nevertheless this massive upgrade from the previous limit of 128,000 tokens means the AI can now read entire codebases or multiple long documents in a single conversation.
01. Better at Coding and Following Instructions
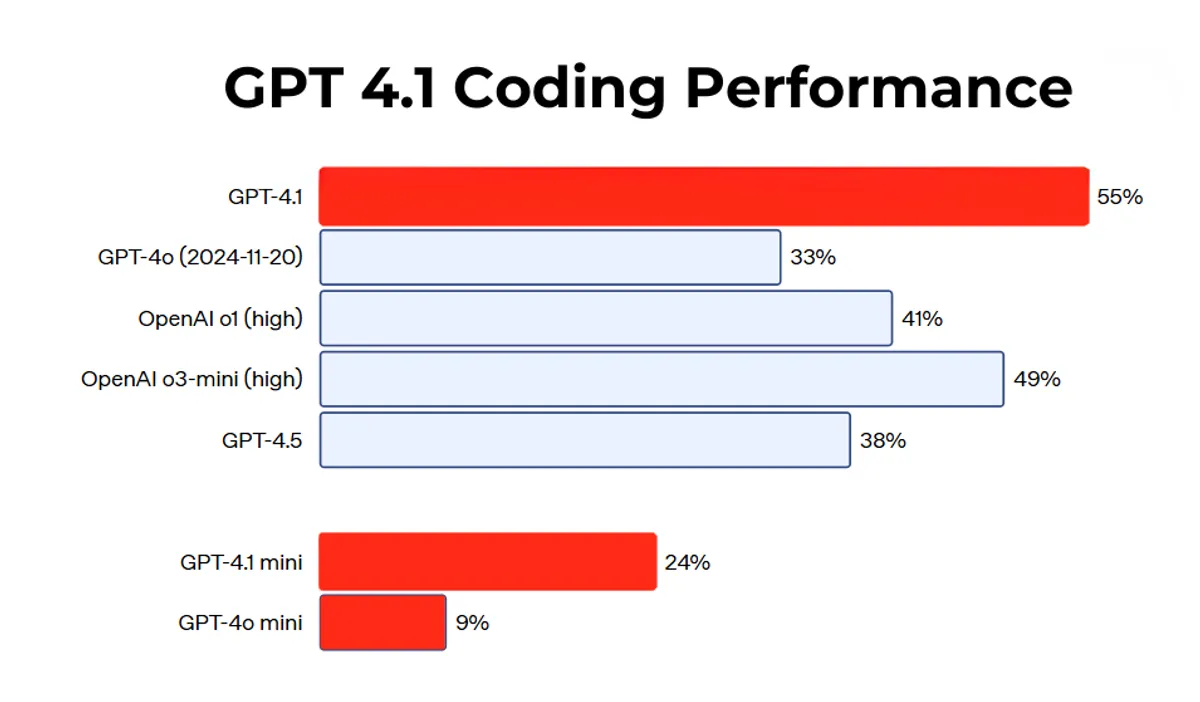
One of the biggest improvements in GPT-4.1 is its coding ability. On the SWE-bench Verified test, a measure of real-world software engineering skills, GPT-4.1 completes 54.6% of tasks, compared to just 33.2% for the previous GPT-4o model.
This 21.4% improvement represents a significant leap forward in the AI’s ability to write, understand, and fix code.
The model is not just better at writing code, but also at reviewing it. In a head-to-head test using 200 real GitHub pull requests, GPT-4.1 was judged to provide better code review suggestions than Anthropic’s Claude 3.7 Sonnet in 54.9% of cases.
02. More Affordable Pricing
Another key change is pricing. GPT-4.1 is 26% less expensive than GPT-4o for typical uses, and GPT-4.1 nano is OpenAI’s cheapest and fastest model ever.
GPT-4.1 costs $2 per million input tokens and $8 per million output tokens. GPT-4.1 mini is $0.40 per million input tokens and $1.60 per million output tokens, while GPT-4.1 nano is just $0.10 per million input tokens and $0.40 per million output tokens.
03. Improved Video Understanding
GPT-4.1 has impressive video comprehension abilities. In OpenAI’s tests for video understanding (called Video-MME), GPT-4.1 scored 72% accuracy in the “long, no subtitles” category, showing it can understand 30–60 minute videos without relying on text.
04. Fewer Errors in Code
Beyond the benchmark improvements, GPT-4.1 makes significantly fewer unnecessary changes when editing code. Internal evaluations showed extraneous edits dropped from 9% with GPT-4o to just 2% with GPT-4.1.
05. Fine-tuning Support
Microsoft (a major investor in OpenAI) announced that Azure will support fine-tuning for GPT-4.1 and GPT-4.1 mini, allowing businesses to customize these models for their specific needs.
Which one is better… GPT-4.1 or Claude 3.7?
While GPT-4.1 is a strong performer, Anthropic’s Claude 3.7 Sonnet still edges it out on some coding benchmarks, scoring around 62–63% on SWE-bench compared to GPT-4.1’s 54.6%.
However, in practical code review tasks, GPT-4.1’s focus on actionable, relevant feedback gives it a real-world edge. Developers found its reviews more useful and less noisy than those from Claude.
What are GPT 4.1 Token Context Limits?
GPT-4.1 models lead significantly in input token capacity with a maximum of 1 million tokens, making them ideal for processing massive codebases or lengthy documents.
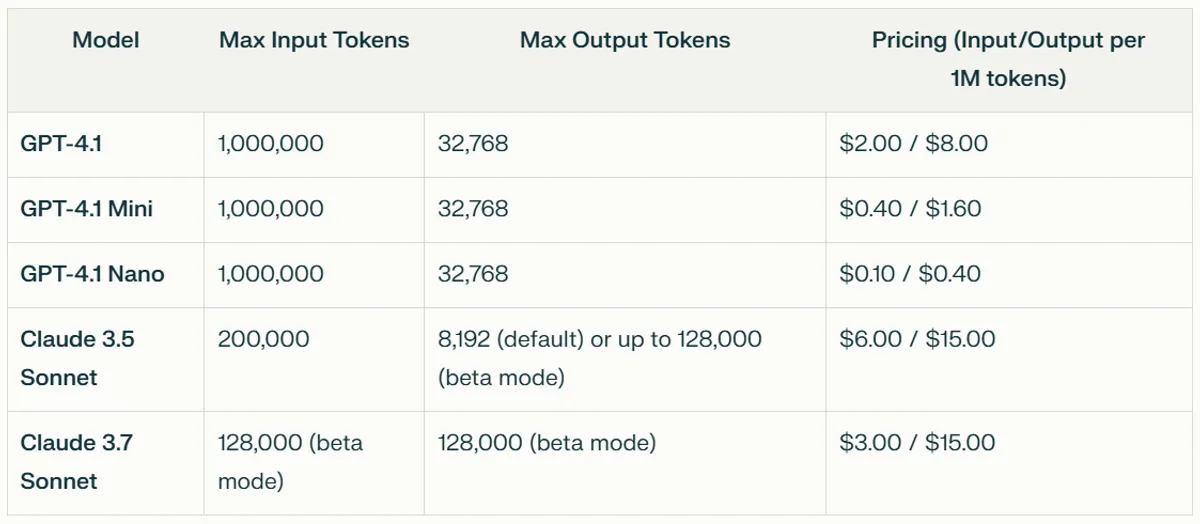
GPT-4.1 models allow only up to 32,768 output tokens, Claude models excel in extended outputs with up to 128,000 tokens in beta mode for both Claude 3.5 and Claude 3.7.
Claude models are significantly more expensive: Claude 3.5 costs $6 per million input tokens and $15 per million output tokens, while Claude 3.7 reduces input cost to $3 but retains the same high output cost.